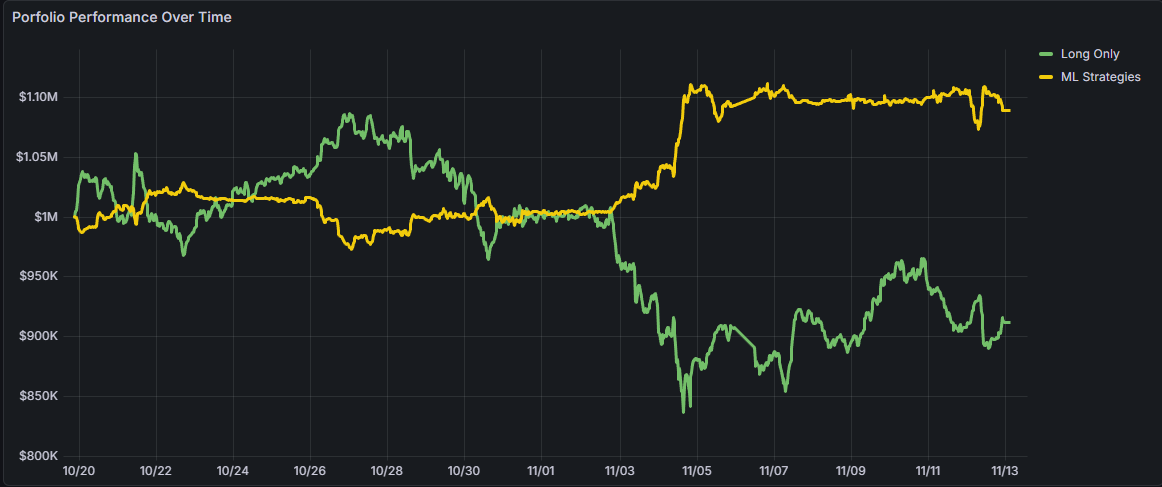
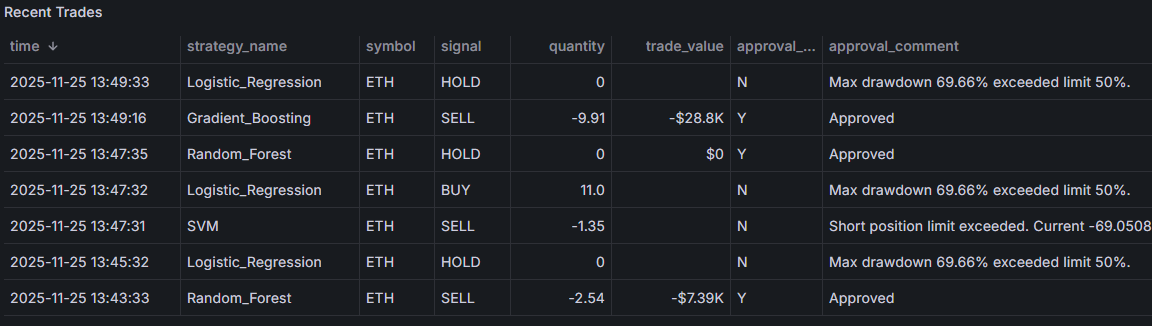
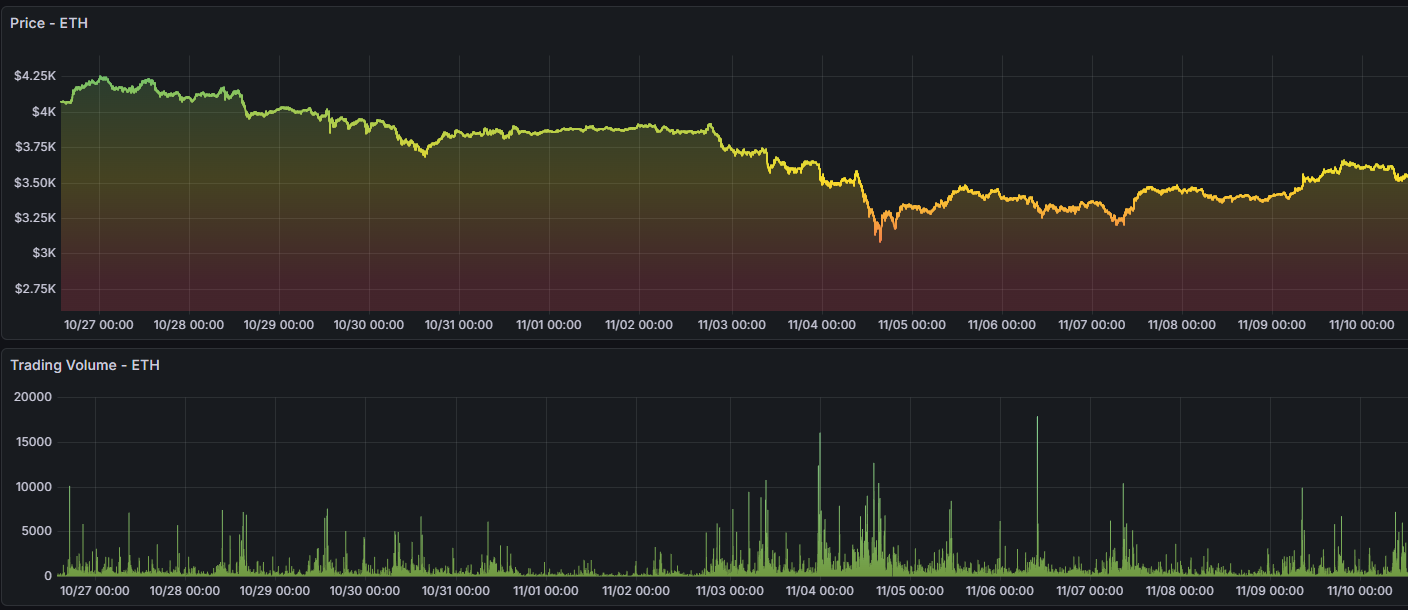
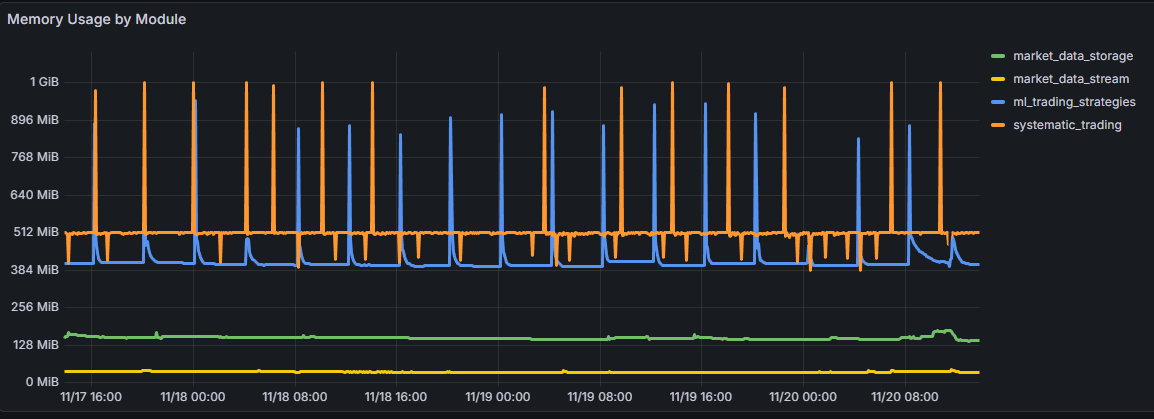
About
I specialize in prediction market trading, analytics, and tooling.
Please reach out if you'd like to connect!
Professional Experience
2026–Present
Helping build out DraftKings Predictions, with a focus on market making.
2025–2026
Founded a prediction market intelligence platform, featuring an LLM-powered aggregation engine surfacing thousands of cross-exchange arbitrage opportunities. Archived at predidesk.com.
Summer 2025
Developed Treasury Futures pricing engines and automated VaR ETL pipelines.
Winter 2025
Built deep generative frameworks (GANs) to model implied volatility surfaces.
2022–2024
Optimized forecasting decision tree models and refactored big data SQL workflows.
2019–2022
Managed critical databases, created API dashboards, and designed regression pricing models.
Education
2025
2019